Le deep learning révolutionne aujourd’hui notre façon de concevoir l’intelligence artificielle et transforme radicalement de nombreux secteurs d’activité. Cette technologie d’apprentissage profond, qui imite le fonctionnement du cerveau humain à travers des réseaux de neurones artificiels, représente l’une des avancées les plus significatives de notre époque numérique.
Avec un marché qui a atteind 126 milliards de dollars en fin 2025 selon les dernières projections, le deep learning n’est plus une simple curiosité technologique mais une nécessité stratégique pour les entreprises qui souhaitent rester compétitives. Que vous soyez dirigeant d’entreprise, développeur, data scientist ou simplement curieux de comprendre cette révolution technologique, ce guide complet vous permettra de maîtriser tous les aspects de l’apprentissage profond.
- Qu'est-ce que le deep learning ?
- Deep learning vs Machine learning : comprendre les différences
- Les types de réseaux de neurones en deep learning
- Applications concrètes du deep learning en 2026
- Outils et frameworks incontournables en 2026
- Défis et limitations actuels
- Tendances et innovations pour 2025-2030
- Guide pratique : démarrer avec le deep learning
- Implications business et stratégiques autour du deep learning
- Cas d'études approfondis sur le deep learning
- Perspectives d'avenir et recommandations
- Deep Learning : questions fréquentes
Qu’est-ce que le deep learning ?
Définition et principes fondamentaux
Le deep learning, ou apprentissage profond en français, constitue une branche avancée du machine learning qui utilise des réseaux de neurones artificiels à plusieurs couches pour analyser et interpréter des données complexes. Contrairement aux algorithmes traditionnels de machine learning qui nécessitent une extraction manuelle des caractéristiques, le deep learning peut automatiquement découvrir des patterns cachés dans les données.

Cette technologie s’inspire directement du fonctionnement du cerveau humain, où des milliards de neurones interconnectés traitent l’information de manière parallèle. Dans le contexte numérique, ces « neurones artificiels » sont organisés en couches successives qui transforment progressivement les données d’entrée en informations exploitables.
Architecture des réseaux de neurones profonds
Un réseau de neurones profond se compose généralement de trois types de couches principales. La couche d’entrée reçoit les données brutes, qu’il s’agisse d’images, de texte, de signaux audio ou de toute autre forme d’information numérique. Les couches cachées, dont le nombre peut varier de quelques unités à plusieurs centaines selon la complexité du problème, effectuent les transformations et calculs nécessaires à l’extraction des caractéristiques pertinentes. Enfin, la couche de sortie produit le résultat final, que ce soit une classification, une prédiction ou une génération de contenu.
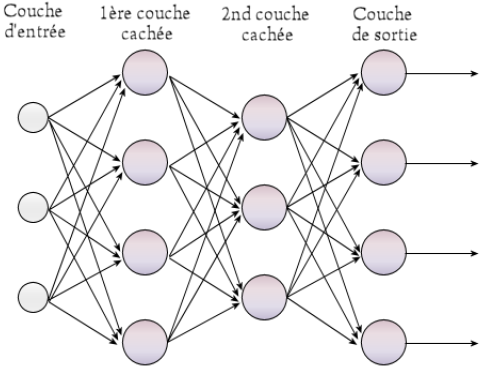
Chaque neurone artificiel applique une fonction mathématique aux données qu’il reçoit, pondère ces informations selon des paramètres appris durant l’entraînement, puis transmet le résultat aux neurones de la couche suivante. Cette architecture en couches multiples permet au système d’apprendre des représentations de plus en plus abstraites et sophistiquées des données.
Deep learning vs Machine learning : comprendre les différences
Approches méthodologiques distinctes
Bien que le deep learning soit une sous-catégorie du machine learning, ces deux approches diffèrent fondamentalement dans leur méthodologie. Le machine learning traditionnel requiert généralement une phase préparatoire importante où les ingénieurs doivent identifier et extraire manuellement les caractéristiques pertinentes des données. Cette étape, appelée « feature engineering », demande une expertise métier approfondie et peut représenter 80% du temps consacré à un projet.
Le deep learning, au contraire, automatise cette extraction de caractéristiques grâce à ses couches multiples. Le réseau apprend lui-même à identifier les patterns les plus significatifs, libérant ainsi les data scientists de cette tâche fastidieuse et souvent subjective. Cette autonomie permet de traiter des données non structurées comme les images, la parole ou le langage naturel avec une efficacité remarquable.
Performance et complexité
En termes de performance, le deep learning excelle particulièrement lorsque les volumes de données sont importants. Alors que les algorithmes de machine learning traditionnel atteignent rapidement un plateau de performance, les modèles de deep learning continuent de s’améliorer avec l’augmentation des données d’entraînement. Cette capacité d’amélioration continue explique pourquoi les géants technologiques investissent massivement dans la collecte et le stockage de données.
Cependant, cette puissance a un coût : les modèles de deep learning nécessitent des ressources computationnelles considérables et des temps d’entraînement prolongés. Ils fonctionnent également comme des « boîtes noires », rendant difficile l’interprétation de leurs décisions, contrairement aux algorithmes de machine learning traditionnel qui offrent souvent une meilleure explicabilité.
Les types de réseaux de neurones en deep learning
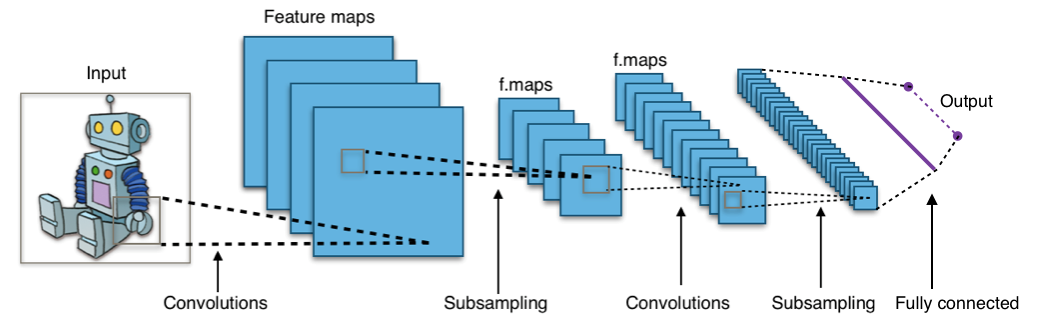
Réseaux de neurones convolutionnels (CNN)
Les réseaux de neurones convolutionnels représentent l’architecture de référence pour le traitement d’images et de données spatiales. Inspirés du système visuel des mammifères, les CNN utilisent des filtres convolutionnels qui glissent sur l’image pour détecter des caractéristiques locales comme les contours, les textures ou les formes géométriques.
Cette architecture présente plusieurs avantages décisifs : la invariance à la translation permet de reconnaître un objet indépendamment de sa position dans l’image, tandis que le partage de paramètres réduit considérablement le nombre de variables à apprendre. Les couches de pooling réduisent progressivement la dimensionnalité des données tout en conservant les informations essentielles.
Les CNN trouvent leurs applications dans la reconnaissance d’images médicales, où ils détectent des tumeurs avec une précision parfois supérieure à celle des radiologues expérimentés, dans la vision par ordinateur pour les véhicules autonomes, ou encore dans l’analyse de contenus pour les réseaux sociaux.
Réseaux de neurones récurrents (RNN) et LSTM
Pour traiter des données séquentielles comme le langage naturel, la musique ou les séries temporelles, les réseaux de neurones récurrents s’imposent comme la solution de choix. Contrairement aux réseaux classiques qui traitent chaque input indépendamment, les RNN maintiennent une « mémoire » des inputs précédents grâce à leurs connexions récurrentes.
Les réseaux LSTM (Long Short-Term Memory) représentent une évolution sophistiquée des RNN traditionnels. Ils résolvent le problème du gradient qui disparaît lors de l’entraînement sur de longues séquences grâce à leur architecture complexe comprenant des « portes » qui contrôlent le flux d’information. Cette innovation permet de capturer des dépendances à long terme dans les données séquentielles.
Ces architectures alimentent aujourd’hui les assistants vocaux comme Siri ou Alexa, les systèmes de traduction automatique qui rivalisent avec les traducteurs humains, et les modèles de génération de texte qui produisent des contenus d’une qualité surprenante.
Transformers et attention mechanisms
L’architecture Transformer, introduite en 2017, a révolutionné le traitement du langage naturel et s’étend aujourd’hui à de nombreux autres domaines. Le mécanisme d’attention permet au modèle de se concentrer sur les parties les plus pertinentes de l’input, indépendamment de leur position dans la séquence.
Cette approche présente des avantages considérables : elle permet un traitement parallélisé qui accélère significativement l’entraînement, capture efficacement les relations à long terme dans les données, et s’adapte naturellement à des inputs de longueur variable. Les Transformers ont donné naissance aux modèles de langage génératifs comme GPT, qui démontrent des capacités remarquables de compréhension et de génération de texte.
Applications concrètes du deep learning en 2026
Secteur de la santé : diagnostic et traitement personnalisé
Le domaine médical connaît une transformation radicale grâce au deep learning. Les systèmes d’imagerie médicale assistés par IA atteignent aujourd’hui des taux de précision exceptionnels dans la détection précoce de cancers. L’exemple de Google DeepMind est particulièrement frappant : leur algorithme détecte le cancer du sein avec une précision de 94,5%, réduisant les faux positifs de 5,7% et les faux négatifs de 9,4% par rapport aux radiologues humains.
Au-delà du diagnostic, le deep learning révolutionne la découverte de médicaments. AlphaFold, développé par DeepMind, prédit la structure 3D des protéines avec une précision remarquable, accélérant potentiellement le développement de nouveaux traitements. Cette avancée, qui a valu le prix Nobel de chimie 2024 à ses créateurs, pourrait réduire le temps de développement des médicaments de 10-15 ans à quelques années seulement.
La médecine personnalisée bénéficie également de ces avancées. Les algorithmes analysent les données génomiques, les historiques médicaux et les données de wearables pour proposer des traitements adaptés à chaque patient. Cette approche individualisée améliore l’efficacité thérapeutique tout en réduisant les effets secondaires.
Finance et fintech : détection de fraude et trading algorithmique
L’industrie financière exploite massivement le deep learning pour sécuriser les transactions et optimiser les investissements. Les systèmes de détection de fraude analysent en temps réel des millions de transactions, identifiant des patterns suspects avec une précision qui dépasse largement les méthodes traditionnelles. Ces algorithmes peuvent détecter des fraudes sophistiquées qui échapperaient à l’analyse humaine, comme les attaques coordonnées ou les techniques d’ingénierie sociale avancées.
Le trading algorithmique représente un autre domaine d’application majeur. Les hedge funds utilisent des réseaux de neurones pour analyser d’énormes volumes de données market, incluant les actualités, les réseaux sociaux, les données macroéconomiques et les patterns historiques. Ces systèmes peuvent identifier des opportunités d’arbitrage en millisecondes et exécuter des stratégies de trading complexes.
Les services bancaires s’améliorent également grâce à l’IA conversationnelle. Les chatbots financiers, alimentés par des modèles de langage avancés, gèrent désormais 67% des demandes clients de premier niveau, offrant une disponibilité 24/7 et des réponses personnalisées basées sur l’historique et le profil de chaque client.
Industrie automobile : conduite autonome et maintenance prédictive
Les véhicules autonomes représentent l’une des applications les plus visibles du deep learning. Tesla, Waymo et d’autres constructeurs utilisent des réseaux de neurones convolutionnels pour interpréter les données de multiples caméras, lidars et radars. Ces systèmes doivent prendre des décisions critiques en temps réel : reconnaître les piétons, anticiper les comportements des autres conducteurs, naviguer dans des conditions météorologiques difficiles.
L’efficacité de ces systèmes s’améliore constamment grâce à l’apprentissage fédéré. Chaque véhicule contribue à l’amélioration du modèle global en partageant ses expériences de conduite, créant un effet de réseau où chaque kilomètre parcouru bénéficie à l’ensemble de la flotte.
La maintenance prédictive transforme également l’industrie automobile. Les capteurs embarqués collectent des données sur les performances des composants, et les algorithmes de deep learning prédisent les défaillances avant qu’elles ne surviennent. Cette approche réduit les coûts de maintenance de 25% et améliore la disponibilité des véhicules.
E-commerce et retail : personnalisation et logistique
Le e-commerce exploite le deep learning pour créer des expériences d’achat hautement personnalisées. Amazon utilise des algorithmes sophistiqués qui analysent les comportements de navigation, les historiques d’achat, les évaluations et même les temps de pause sur certains produits pour recommander des articles avec une précision remarquable. Ces systèmes de recommandation génèrent 35% du chiffre d’affaires d’Amazon.
La recherche visuelle révolutionne également l’expérience client. Les consommateurs peuvent désormais photographier un article qui les intéresse et trouver instantanément des produits similaires ou identiques. Pinterest Lens, Google Lens et les applications de mode comme Stylumia exploitent cette technologie pour créer des expériences d’achat innovantes.
L’optimisation de la chaîne logistique bénéficie également du deep learning. Les algorithmes prédisent la demande avec une granularité géographique et temporelle fine, optimisent les stocks pour éviter les ruptures et les surstocks, et planifient les livraisons pour minimiser les coûts et les délais. Amazon a ainsi réduit ses coûts logistiques de 20% grâce à ces optimisations.
Créativité et divertissement : génération de contenu
L’industrie créative connaît une révolution avec l’émergence des outils de génération de contenu par IA. DALL-E, Midjourney et Stable Diffusion permettent de créer des images de qualité professionnelle à partir de simples descriptions textuelles. Ces outils démocratisent la création visuelle et ouvrent de nouvelles possibilités créatives.
La génération de musique progresse également rapidement. AIVA compose des musiques classiques, pop ou jazz adaptées à différents contextes : films, jeux vidéo, publicités. Ces compositions, techniquement irréprochables, soulèvent des questions intéressantes sur la nature de la créativité artistique.
L’industrie du jeu vidéo exploite le deep learning pour créer des personnages non-joueurs (PNJ) plus intelligents et réactifs. Ces NPCs apprennent des comportements des joueurs et s’adaptent dynamiquement, créant des expériences de jeu plus immersives et imprévisibles.
Outils et frameworks incontournables en 2026
TensorFlow : l’écosystème Google
TensorFlow reste la plateforme de référence pour le développement de modèles de deep learning à grande échelle. Développé par Google, cet framework open-source offre une flexibilité remarquable, permettant de déployer des modèles sur des environnements variés : serveurs cloud, appareils mobiles, navigateurs web ou même microcontrôleurs.
Les améliorations de 2026 incluent une meilleure intégration avec les TPUs (Tensor Processing Units) de Google, une optimisation automatique des modèles pour différentes architectures matérielles, et des outils simplifiés pour l’apprentissage fédéré. TensorFlow Lite permet désormais d’exécuter des modèles complexes sur smartphones avec une consommation énergétique réduite de 40%.
L’écosystème TensorFlow comprend également TensorBoard pour la visualisation des entraînements, TensorFlow Extended (TFX) pour les pipelines de production, et TensorFlow Quantum pour l’exploration du machine learning quantique. Cette richesse fonctionnelle explique pourquoi 69% des entreprises utilisent TensorFlow pour leurs projets de deep learning.
PyTorch : flexibilité et recherche
PyTorch, développé par Meta (anciennement Facebook), s’impose comme l’outil favori des chercheurs et des équipes nécessitant une grande flexibilité. Son approche « define-by-run » permet de modifier dynamiquement l’architecture du réseau pendant l’exécution, facilitant l’expérimentation et le prototypage rapide.
Les nouveautés 2026 de PyTorch incluent PyTorch 2.0 avec des optimisations de compilation qui accélèrent l’entraînement de 30%, une meilleure intégration avec les environnements cloud, et des outils simplifiés pour la quantification des modèles. PyTorch Lightning abstrait les aspects techniques répétitifs, permettant aux développeurs de se concentrer sur l’architecture des modèles.
L’écosystème PyTorch comprend torchvision pour la vision par ordinateur, torchaudio pour le traitement audio, et torchtext pour le NLP. Cette spécialisation par domaine accélère le développement et assure la compatibilité avec les meilleures pratiques de chaque secteur.
Frameworks émergents et spécialisés
JAX, développé par Google Research, gagne en popularité grâce à sa capacité à compiler automatiquement les fonctions Python vers des accélérateurs comme les GPUs et TPUs. Sa philosophie fonctionnelle et ses transformations automatiques (autodiff, vectorisation, parallélisation) séduisent les chercheurs travaillant sur des algorithmes complexes.
Hugging Face Transformers s’impose comme la référence pour les modèles de langage. Cette bibliothèque offre un accès simplifié à des milliers de modèles pré-entraînés : BERT, GPT, T5, et bien d’autres. L’intégration avec les plateformes cloud et les outils de déploiement facilite grandement le passage de la recherche à la production.
PaddlePaddle, développé par Baidu, se distingue par ses optimisations pour les marchés asiatiques et ses outils spécialisés pour l’industrie. MLX d’Apple cible spécifiquement les puces Apple Silicon, offrant des performances optimales sur les Mac équipés de puces M-series.
Défis et limitations actuels
Besoins computationnels et consommation énergétique
L’entraînement des modèles de deep learning modernes nécessite des ressources computationnelles considérables. GPT-4 aurait coûté plus de 100 millions de dollars à entraîner, nécessitant des milliers de GPUs pendant plusieurs mois. Cette course à la puissance de calcul pose des défis économiques et environnementaux majeurs.
La consommation énergétique représente une préoccupation croissante. L’entraînement d’un modèle de langage de grande taille peut consommer autant d’énergie qu’une ville de 100 000 habitants pendant une journée. Les entreprises technologiques investissent massivement dans des solutions plus efficaces : puces spécialisées, architectures optimisées, techniques de quantification et d’élagage des modèles.
Les solutions émergentes incluent l’apprentissage par transfert qui réutilise les connaissances de modèles existants, l’apprentissage fédéré qui distribue l’entraînement, et les nouvelles architectures comme les Mixture of Experts qui n’activent que les parties nécessaires du modèle pour chaque tâche.
Qualité et biais des données
Les modèles de deep learning ne sont aussi bons que les données sur lesquelles ils sont entraînés. Les biais présents dans les données d’entraînement se reflètent inévitablement dans les prédictions du modèle, pouvant perpétuer ou amplifier des discriminations existantes. Les systèmes de reconnaissance faciale montrent par exemple des taux d’erreur plus élevés pour certaines ethnies, reflétant des déséquilibres dans les données d’entraînement.
La curation de données de qualité représente un défi majeur. Il faut nettoyer les données, détecter les outliers, gérer les données manquantes et assurer la représentativité de l’échantillon. Cette tâche, souvent sous-estimée, peut représenter 60% de l’effort total d’un projet de machine learning.
Les techniques d’augmentation de données artificielles, les méthodes de détection de biais automatisées et les approches d’apprentissage équitable (fair learning) émergent comme des solutions prometteuses pour adresser ces défis.
Explicabilité et confiance
Les modèles de deep learning fonctionnent comme des « boîtes noires », rendant difficile la compréhension de leurs décisions. Cette opacité pose des problèmes majeurs dans des domaines critiques comme la santé, la justice ou la finance, où il est essentiel de pouvoir expliquer et justifier les décisions automatisées.
L’IA explicable (XAI) développe des techniques pour rendre les modèles plus interprétables : visualisation des caractéristiques importantes, génération d’explications textuelles, identification des exemples similaires dans les données d’entraînement. LIME et SHAP sont devenus des outils standard pour analyser les prédictions de modèles complexes.
Cependant, il existe souvent un compromis entre performance et explicabilité. Les modèles les plus performants sont généralement les moins explicables, obligeant les praticiens à faire des choix difficiles selon le contexte d’application.
Tendances et innovations pour 2025-2030
Intelligence artificielle générale (AGI)
La quête de l’intelligence artificielle générale, capable de résoudre n’importe quelle tâche cognitive humaine, mobilise les plus grands laboratoires de recherche. OpenAI, Google DeepMind, Anthropic et d’autres investissent des milliards dans cette direction. Les modèles multimodaux comme GPT-4o ou Gemini Pro montrent des capacités émergentes prometteuses, combinant compréhension textuelle, visuelle et raisonnement logique.
Les approches actuelles explorent l’apprentissage par renforcement avancé, les architectures neuromorphiques qui imitent plus fidèlement le cerveau biologique, et les systèmes multi-agents où plusieurs IAs spécialisées collaborent. L’objectif est de créer des systèmes capables d’apprentissage continu, de transfert de connaissances entre domaines et d’adaptation rapide à de nouvelles situations.
Cependant, de nombreux experts estiment que l’AGI reste encore éloignée, nécessitant des percées fondamentales en neurosciences, psychologie cognitive et informatique théorique.
Edge computing et IA embarquée
La démocratisation de l’IA passe par sa disponibilité sur tous types d’appareils, des smartphones aux objets connectés. Les puces spécialisées comme les Neural Processing Units (NPUs) intégrées dans les derniers processeurs permettent d’exécuter des modèles de deep learning localement, sans connexion cloud.
Cette évolution présente des avantages considérables : réduction de la latence, protection de la vie privée, fonctionnement hors ligne et réduction des coûts de bande passante. Apple Neural Engine, Google Tensor ou Qualcomm AI Engine illustrent cette tendance vers l’IA décentralisée.
L’optimisation des modèles pour l’edge computing progresse rapidement : quantification, pruning, distillation de connaissances et architectures efficaces comme MobileNets permettent de faire fonctionner des modèles sophistiqués sur des appareils aux ressources limitées.
Apprentissage auto-supervisé et few-shot learning
L’apprentissage auto-supervisé révolutionne la façon dont les modèles apprennent. Au lieu de nécessiter d’énormes datasets étiquetés manuellement, ces techniques utilisent la structure intrinsèque des données pour créer des tâches d’apprentissage automatiques. GPT apprend ainsi en prédisant le mot suivant dans un texte, tandis que les modèles de vision apprennent en reconstituant des images partiellement masquées.
Le few-shot learning permet aux modèles d’apprendre de nouvelles tâches avec seulement quelques exemples, mimant la capacité humaine d’apprentissage rapide. Cette approche réduit drastiquement les besoins en données étiquetées et accélère le déploiement de l’IA dans de nouveaux domaines. Ces avancées ouvrent la voie à des systèmes d’IA plus flexibles et adaptables, capables d’apprendre continuellement de leur environnement sans supervision humaine intensive.
Calcul quantique et deep learning
L’informatique quantique promet d’accélérer exponentiellement certains calculs de machine learning. Les algorithmes quantiques pourraient résoudre des problèmes d’optimisation complexes, accélérer l’entraînement de certains types de modèles et permettre de nouvelles architectures neurales impossibles avec l’informatique classique.
IBM, Google, Microsoft et d’autres géants investissent dans des plateformes de machine learning quantique. TensorFlow Quantum, PennyLane et Qiskit Machine Learning offrent déjà des outils pour expérimenter avec ces technologies émergentes.
Cependant, l’informatique quantique reste largement expérimentale, avec des défis majeurs à surmonter : stabilité des qubits, correction d’erreurs quantiques et développement d’algorithmes pratiques. Les applications commerciales ne sont probablement pas attendues avant la fin de la décennie.
Guide pratique : démarrer avec le deep learning
Formation et compétences nécessaires
Se lancer dans le deep learning nécessite une base solide en mathématiques, particulièrement en algèbre linéaire, calcul différentiel et statistiques. La compréhension des concepts de probabilités, d’optimisation et de théorie de l’information est également essentielle. Heureusement, de nombreuses ressources permettent d’acquérir ces connaissances progressivement.
Les compétences en programmation sont indispensables, Python étant devenu le langage de référence grâce à ses bibliothèques spécialisées et sa syntaxe accessible. La maîtrise de NumPy pour le calcul numérique, Pandas pour la manipulation de données et Matplotlib pour la visualisation constitue un prérequis minimal. Les plateformes d’apprentissage en ligne offrent des parcours structurés : Coursera propose le célèbre cours de Andrew Ng, Fast.ai privilégie une approche pratique, tandis qu’edX et Udacity offrent des programmes complets. Les MOOCs du MIT, Stanford et autres universités prestigieuses sont également librement accessibles.
Ressources et communautés
La communauté du deep learning est particulièrement active et bienveillante. Les forums comme Reddit r/MachineLearning, Stack Overflow et les discussions GitHub permettent d’obtenir de l’aide sur des problèmes spécifiques. Twitter abrite une communauté active de chercheurs et praticiens qui partagent régulièrement leurs découvertes et insights.
Les conférences comme NeurIPS, ICML, ICLR et CVPR rassemblent les meilleurs chercheurs mondiaux. Leurs présentations, souvent disponibles en ligne, offrent un aperçu des dernières avancées. Les meetups locaux et les groupes d’utilisateurs permettent de créer un réseau professionnel et d’échanger avec des praticiens. Kaggle mérite une mention spéciale : cette plateforme propose des compétitions de machine learning avec des datasets réels et des prix attractifs. Participer à ces concours permet d’acquérir une expérience pratique et de benchmarker ses compétences contre des experts mondiaux.
Projets pour débuter
Commencer par des projets simples mais concrets permet de maîtriser progressivement les outils et concepts. La classification d’images avec le dataset CIFAR-10 ou MNIST constitue un excellent point de départ : ces problèmes sont suffisamment simples pour être accessibles aux débutants tout en illustrant les concepts fondamentaux.
L’analyse de sentiments sur des avis clients permet d’explorer le traitement du langage naturel. Twitter, Amazon Reviews ou IMDb proposent des datasets étiquetés parfaits pour s’initier aux réseaux de neurones récurrents et aux techniques de preprocessing textuel. Les projets de recommandation, basés sur les données de MovieLens ou Amazon, introduisent les concepts de filtrage collaboratif et d’apprentissage de représentations. Ces applications concrètes permettent de comprendre comment l’IA améliore l’expérience utilisateur dans des contextes réels.
Infrastructure et outils de déploiement
L’infrastructure cloud démocratise l’accès aux ressources computationnelles nécessaires au deep learning. Google Colab offre un environnement gratuit avec accès aux GPUs, parfait pour l’apprentissage et le prototypage. Pour des projets plus ambitieux, AWS SageMaker, Google Cloud AI Platform et Azure Machine Learning proposent des solutions complètes intégrant stockage, calcul et déploiement.
Docker révolutionne la reproductibilité des expériences. Containeriser ses modèles assure un fonctionnement identique entre environnements de développement et de production. MLflow et Weights & Biases facilitent le suivi des expériences, la comparaison de modèles et la collaboration en équipe. Le déploiement en production nécessite des outils spécialisés : TensorFlow Serving pour les modèles TensorFlow, TorchServe pour PyTorch, ou des solutions agnostiques comme BentoML. Kubernetes orchestrer le déploiement à grande échelle, garantissant disponibilité et scalabilité.
Implications business et stratégiques autour du deep learning
ROI et justification des investissements
L’investissement dans le deep learning génère des retours mesurables dans de nombreux secteurs. McKinsey estime que l’IA pourrait créer 13 000 milliards de dollars de valeur économique d’ici 2030. Cependant, calculer le ROI spécifique d’un projet de deep learning nécessite une approche structurée.
Les gains de productivité constituent souvent le bénéfice le plus immédiat. L’automatisation de tâches répétitives libère les employés pour des activités à plus forte valeur ajoutée. Un système de reconnaissance automatique de documents peut traiter 1000 fois plus de documents qu’un employé, avec une précision supérieure et un fonctionnement 24/7. L’amélioration de l’expérience client génère également des revenus additionnels. Les systèmes de recommandation augmentent le panier moyen, les chatbots réduisent les coûts de support client, et la personnalisation améliore la fidélisation. Amazon attribue 35% de ses ventes à son système de recommandation.
Transformation des métiers et compétences
Le deep learning transforme profondément le marché du travail, créant de nouveaux métiers tout en modifiant radicalement les existants. Les rôles de Data Scientist, ML Engineer, AI Product Manager et AI Ethics Officer connaissent une croissance explosive. Selon LinkedIn, ces métiers figurent parmi les 15 professions les plus demandées.
Cette transformation nécessite une adaptation des compétences existantes. Les analystes business doivent comprendre les possibilités et limites de l’IA pour identifier les cas d’usage pertinents. Les développeurs traditionnels s’orientent vers le machine learning engineering, maîtrisant les pipelines de données et les outils de déploiement. Les designers UX/UI intègrent les interactions conversationnelles et les interfaces intelligentes. La formation continue devient cruciale pour rester compétitif. Les entreprises investissent massivement dans la montée en compétences de leurs équipes : Google AI Education, Microsoft AI School et AWS Training proposent des parcours certifiants. L’apprentissage en situation de travail, avec des projets pilotes encadrés par des experts, s’avère particulièrement efficace.
Considérations éthiques et réglementaires
L’adoption du deep learning soulève des questions éthiques complexes qui impactent directement la stratégie business. Le Règlement européen sur l’IA, entré en vigueur en 2024, impose des obligations strictes aux entreprises utilisant des systèmes d’IA à haut risque. Les secteurs de la santé, de l’éducation, des ressources humaines et de la sécurité sont particulièrement concernés.
La transparence algorithmique devient un avantage concurrentiel. Les entreprises qui peuvent expliquer leurs décisions automatisées gagnent la confiance des clients et des régulateurs. Cette exigence influence le choix des technologies : privilégier des modèles interprétables ou investir dans des outils d’explicabilité. La gouvernance des données représente un enjeu stratégique majeur. Le RGPD européen, le CCPA californien et les réglementations émergentes imposent des contraintes sur la collecte, le stockage et l’utilisation des données personnelles. Les entreprises développent des frameworks de « Privacy by Design » intégrant ces contraintes dès la conception des systèmes.
Avantage concurrentiel et différenciation
Le deep learning peut créer des avantages concurrentiels durables, mais la fenêtre d’opportunité se réduit rapidement. Les early adopters bénéficient d’un effet d’expérience : plus ils utilisent leurs systèmes, plus ils collectent de données, plus leurs modèles s’améliorent. Cet « effet réseau des données » crée des barrières à l’entrée naturelles.
La différenciation ne réside plus dans l’accès à la technologie, désormais commoditisée, mais dans l’excellence opérationnelle : qualité des données, pertinence des cas d’usage, intégration dans les processus métier, et capacité d’adaptation. Les entreprises qui maîtrisent l’ensemble de la chaîne de valeur de l’IA, de la stratégie data au déploiement en production, prennent une avance significative. L’innovation ouverte devient cruciale. Les partenariats avec des laboratoires de recherche, les acquisitions de startups spécialisées et la participation à des écosystèmes d’innovation permettent de rester à la pointe. Google, Microsoft et Amazon développent des plateformes qui facilitent l’accès à leurs technologies avancées, démocratisant l’IA tout en créant des écosystèmes captifs.
Cas d’études approfondis sur le deep learning
Netflix : personnalisation et optimisation de contenu
Netflix illustre parfaitement l’application stratégique du deep learning. Leur système de recommandation, qui influence 80% du contenu visionné, combine plusieurs techniques avancées. Les réseaux de neurones analysent les préférences implicites des utilisateurs : temps de visionnage, pauses, reprises, abandons. Ces signaux faibles révèlent les goûts réels mieux que les évaluations explicites.
L’innovation va au-delà de la recommandation. Netflix utilise le deep learning pour optimiser la qualité de streaming selon la bande passante disponible, personnaliser les vignettes des films selon les préférences visuelles de chaque utilisateur, et même influencer la création de contenu original. L’analyse des données de visionnage révèle les ingrédients d’un succès : acteurs populaires, genres tendance, durée optimale.

Cette approche data-driven a permis à Netflix de passer de distributeur de contenu à créateur de contenu global, investissant 17 milliards de dollars annuellement dans la production originale guidée par l’intelligence artificielle. Leur retour sur investissement en IA se chiffre en milliards de dollars d’économies sur les coûts d’acquisition client et d’augmentation de la rétention.
Tesla : conduite autonome et manufacturing intelligent
Tesla démontre comment le deep learning peut transformer une industrie traditionnelle. Leur approche de la conduite autonome, basée uniquement sur des caméras et des réseaux de neurones, diverge radicalement de la concurrence qui privilégie les capteurs lidar coûteux. Cette stratégie « vision-first » réduit les coûts tout en permettant des mises à jour over-the-air.
L’apprentissage continu constitue l’avantage clé de Tesla. Chaque véhicule collecte des données de conduite qui améliorent le modèle global. Avec plus de 3 millions de véhicules sur route, Tesla dispose du plus grand dataset de conduite réelle au monde. Cette « data moat » devient infranchissable pour la concurrence.

Au-delà de la conduite autonome, Tesla applique l’IA à toute sa chaîne de valeur. Dans leurs gigafactories, des systèmes de vision identifient les défauts de production en temps réel, les robots apprennent à optimiser leurs mouvements, et la maintenance prédictive évite les arrêts de production. Cette intégration verticale de l’IA explique leur avance technologique et leurs marges supérieures.
DeepMind : de la recherche à l’impact industriel
DeepMind illustre la transition de la recherche fondamentale vers les applications commerciales. Leur algorithme AlphaGo, qui a battu les champions mondiaux de Go, a démontré la capacité du deep learning à maîtriser des domaines nécessitant intuition et créativité. Cette victoire symbolique a catalysé l’intérêt mondial pour l’IA.
Les applications industrielles suivent rapidement. AlphaFold révolutionne la biologie structurale en prédisant la forme des protéines, accélérant la recherche médicale. Leur système d’optimisation énergétique réduit la consommation des datacenters Google de 40%, générant des économies de centaines de millions de dollars. Plus récemment, leurs travaux sur la fusion nucléaire avec ITER, l’optimisation du trafic urbain et la prédiction météorologique montrent comment la recherche en IA peut adresser les grands défis sociétaux tout en créant de la valeur économique.
Perspectives d’avenir et recommandations
Évolution technologique attendue
Les prochaines années verront l’émergence de modèles encore plus performants et efficaces. L’architecture des Transformers continuera d’évoluer avec des innovations comme les Mamba (State Space Models) qui promettent une meilleure efficacité computationnelle. Les modèles multimodaux, capables de traiter simultanément texte, images, audio et vidéo, ouvriront de nouveaux cas d’usage.
L’efficacité énergétique deviendra un critère de performance crucial. Les nouvelles architectures comme les Mixture of Experts, qui n’activent que les parties nécessaires du modèle, et les techniques de quantification extreme permettront de déployer des modèles puissants sur des appareils aux ressources limitées. L’apprentissage continu et l’adaptation dynamique représentent les prochaines frontières. Les modèles apprendront à s’adapter en temps réel à de nouvelles situations sans oublier leurs connaissances antérieures, mimant la flexibilité cognitive humaine.
Stratégies de préparation pour les entreprises
Les entreprises doivent développer une stratégie IA holistique intégrant technologie, talents et culture. La première étape consiste à identifier les cas d’usage à fort impact business, en privilégiant ceux où l’IA apporte une différenciation claire par rapport aux solutions traditionnelles.
L’investissement dans les données constitue un prérequis. Développer une infrastructure data moderne, implémenter des processus de qualité des données et créer une culture data-driven dans l’organisation sont essentiels. Les entreprises qui négligent cet aspect échouent souvent dans leurs projets d’IA. La formation des équipes ne peut être négligée. Au-delà des data scientists, c’est toute l’organisation qui doit comprendre les possibilités et limites de l’IA. Les programmes de sensibilisation, les formations pratiques et les projets pilotes permettent cette montée en compétences progressive.
Impacts sociétaux et responsabilité
Le déploiement massif du deep learning transformera profondément notre société. L’automatisation de nombreuses tâches intellectuelles questionnera la valeur du travail humain et nécessitera une réflexion sur l’évolution des systèmes éducatifs et sociaux.
La concentration du pouvoir technologique entre les mains de quelques entreprises soulève des questions de souveraineté numérique. L’Europe, avec ses initiatives comme Gaia-X et ses investissements dans l’IA souveraine, tente de créer une troisième voie entre les géants américains et chinois. L’impact environnemental de l’IA devient critique. L’entraînement des modèles les plus avancés consomme autant d’énergie que des villes entières. Développer des techniques plus efficaces et utiliser des énergies renouvelables deviennent des impératifs moraux et économiques.
Deep Learning : questions fréquentes
Le deep learning est une technologie d’intelligence artificielle qui utilise des réseaux de neurones artificiels à plusieurs couches pour analyser et interpréter des données complexes. Il permet aux machines d’apprendre automatiquement des patterns dans les données sans programmation explicite.
Le machine learning traditionnel nécessite une extraction manuelle des caractéristiques des données, tandis que le deep learning automatise cette étape grâce à ses réseaux de neurones multicouches. Le deep learning excelle sur les données non structurées comme les images et le texte.
TensorFlow et PyTorch sont les frameworks de référence. Pour débuter, Python avec NumPy, Pandas et Matplotlib est essentiel. Google Colab offre un environnement gratuit avec accès aux GPUs pour l’apprentissage.
Oui, grâce aux solutions cloud et aux modèles pré-entraînés. Les services comme AWS SageMaker, Google Cloud AI et Azure ML démocratisent l’accès. De nombreux cas d’usage ne nécessitent pas d’énormes ressources computationnelles.
Les besoins en données de qualité, les ressources computationnelles importantes, l’explicabilité des modèles et les biais potentiels constituent les défis majeurs. La formation des équipes et l’intégration dans les processus métier sont également critiques.
Il faut quantifier les gains de productivité, les économies de coûts, l’amélioration de l’expérience client et les nouveaux revenus générés. Une approche par étapes avec des projets pilotes permet de valider la valeur avant d’investir massivement.
Le deep learning transforme les métiers plutôt qu’il ne les supprime. Il automatise certaines tâches tout en créant de nouveaux rôles : data scientist, ML engineer, AI product manager. La formation continue devient cruciale pour s’adapter.
La transparence des décisions, la protection de la vie privée, la non-discrimination et l’explicabilité sont essentielles. Le Règlement européen sur l’IA impose des obligations strictes aux entreprises utilisant des systèmes d’IA à haut risque.