
Comment un ordinateur fait-il pour voir ? Quel est le rôle de l’intelligence artificielle dans la vision informatique et quelles sont les applications de ces technologies ? Des questions auxquelles nous allons essayer de répondre dans cet article !
Cet article reprend en grande partie un rapport sur la vision artificielle réalisé par Marie, Ysée et moi-même dans le cadre d’un cours de psychologie cognitive et neurosciences suivi à Campus Tech.
L’intelligence artificielle, c’est quoi ?
Intelligence artificielle par-ci, intelligence artificielle par-là, ce terme ressort parfois à tout les sauces, et parfois ce n’est pas correct. On pourrait résumer l’intelligence artificielle comme la capacité d’une machine à simuler l’intelligence. Pour aller plus loin, il faudrait également définir ce qu’est l’intelligence, mais ce n’est pas vraiment le sujet. C’est un domaine qui fait appel à plusieurs disciplines : informatique appliquée, algorithmie, neurosciences, etc. En fait, les système que nous connaissons aujourd’hui sont pour beaucoup basés sur le fonctionnement de notre cerveau ! La puissance de calcul à notre disposition aujourd’hui permet de développer de tels systèmes ayant la volonté de reproduire l’équivalent d’un cerveau humain ! Par exemple, une intelligence artificielle a réussi à battre des champions de poker ! Si vous souhaitez en connaître davantage sur ce domaine, Microsoft Expériences nous parle de l’intelligence artificielle.

Fonctionnement de la vision humaine
La vue est le sens le plus utilisé par l’Homme, en effet c’est le sens sur lequel on se repose le plus. En effet des neurobiologistes ont mesuré que 30% du cortex cérébral est utilisé pour interpréter ce que l’œil voit, alors que seulement 8% sont consacrés au traitement des informations tactiles et 3% aux informations auditives.
L’œil est un système optique relativement basique qui a le don de transformer la lumière des photons en image en pixels. L’œil a une résolution de 576 mégapixels ce qui est très important.
La cornée et le cristallin sont deux éléments de l’œil qui permettent de dévier les rayons lumineux pour les faire atterrir et les concentrés sur la rétine, ces deux éléments fonctionnent comme deux lentilles. La cornée se charge de 80% de la déviation, le reste est pris en charge par le cristallin qui s’adapte à la vision de près ou de loin. Pour la vision de près le cristallin doit converger et pour la vision de loin il doit diverger afin que les rayons atterrissent pile sur la rétine. Se forme alors une image sur la rétine qui est renversée de ce que l’on voit. Ensuite la lumière doit parvenir dans la profondeur de la rétine, où se trouvent les photorécepteurs (seuls 10% de rayons y parviennent).
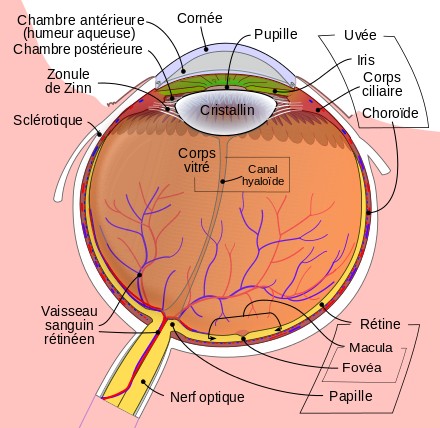
Il existe deux types de photorécepteurs, les cônes qui détectent la couleur et les bâtonnets qui détectent l’intensité de la lumière. Ces récepteurs émettent une impulsion nerveuse, qu’ils transmettent d’abord à d’autres neurones de la rétine qui forment une première synthèse de ces signaux puis relaient chacune l’information a des cellules qui forment le nerf optique qui termine sa course dans les aires visuelle du cerveau.
Il existe trois cônes différents qui captent chacun une couleur différente : le bleu, le rouge et le vert. Les trois cônes permettent de percevoir les longueurs d’ondes entre 400 et 700 nm. Pour finir, une analyse de ce qu’on a vu se met en place. L’œil perçoit mais c’est le cerveau qui donne du sens à l’image.
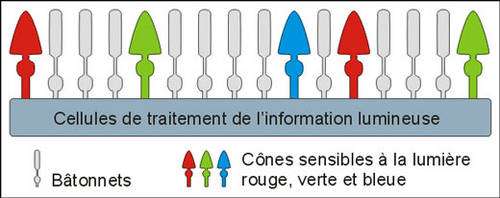
Notre champ de vision s’étend jusqu’à 110° avec une vision monoculaire où chacun des deux yeux est utilisé séparément. Ensuite on passe à une vision binoculaire, cette vision utilise les deux yeux simultanément, elle nous permet une discrimination des couleurs de 60 à 30° environ puis une reconnaissance des symboles de 30 à 5° et une lecture de 20 à 10°. Entre 3 et 5° on parle d’une acidité maximum.
Chaque vision de chaque personne est plus ou moins différente car notre vision peut dépendre de deux processus : le processus descendant, l’idée que nous percevons les choses en fonction de nos attentes et de nos croyances ce qui créent des filtres par lesquels passent nos sensations. Quant au deuxième processus qui est le processus ascendant, est lui au contraire l’idée qu’aucun filtre n’intervient et que nous reconnaissons un objet grâce à ses caractéristiques propres.
Chaque œil est connecté aux deux hémisphères cérébraux via le nerf optique. Ce qui est perçu du côté nasal de chaque œil est envoyé à l’hémisphère opposé et ce qui est perçu du coté temporal est envoyé dans l’hémisphère se situant du même côté que l’œil.
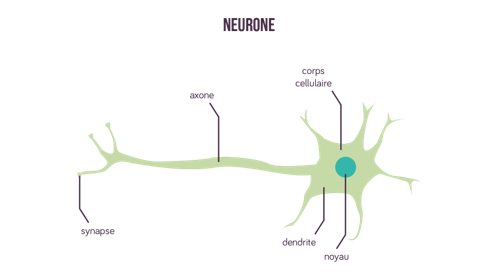
Voici le schéma d’un neurone chez les vertébrés, où chaque éléments possède un rôle comme nous allons le voir dans le cas de la vision artificielle dans les systèmes d’intelligence artificielle :
Fonctionnement de la vision artificielle
En informatique, une image est composée de pixels en largeur et en hauteur. Un pixel est une unité carrée qui est la plus petite composante d’une image codée en RVB : trois couleurs primaires (dont l’échelle va de zéro à 255) dont le mélange forme une couleur parmi environ 16 700 000 couleurs. Une image en informatique a trois dimensions : largeur, hauteur, couleur).
La vision artificielle par ordinateur s’appuie sur le modèle des vertébrés avec notamment des réseaux de neurones. C’est une association de neurones formels ayant un nombre de neurones et un nombre de boucles différents. En informatique, on parle de neurones formels qui sont des représentations informatiques d’un neurone biologique. Ils possèdent plusieurs entrées ainsi qu’une sortie, correspondant respectivement aux dendrites et à un axone.
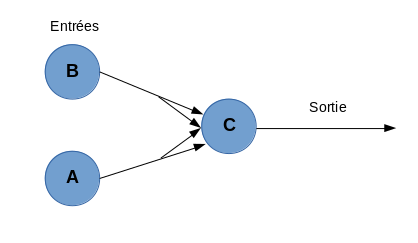
Comme pour un neurone biologique, il agit si ses entrées dépassent un certain seuil. Dans le cas de la vision artificielle, le système neuronal utilisé est le perceptron multicouches, mis au point en 1986 par David Rumelhart.
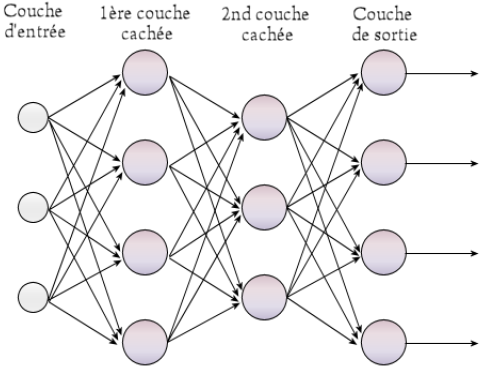
Dans ce modèle, tous les neurones d’une couche sont reliés à tous les neurones des couches adjacentes. Le réseau est soumis à un algorithme de rétropropagation, qui va déterminer les poids minimum pour activer ces neurones formels et les activer ou non.
Cela va permettre de classer différentes données selon certaines étiquettes. Le système va observer chacune des données et met à jour le poids de chaque neurone formel afin de classifier une base de données.
Cependant pour découper une image, on va avoir besoin d’un réseau de neurones convolutifs, qui est plus efficace car il demande moins d’opérations ; il permet d’extraire les caractéristiques qui seront classifiées par le perceptron multicouches.
Grâce à ce réseau neuronal, l’ordinateur va analyser une image avec la convolution. C’est un filtrage qui prend la forme d’un carré qui va se balader dans toute l’image ; il va faire une opération avec tous les pixels qu’il couvre. Ce qui en sortira aura des dimensions plus petites que l’image analysée.
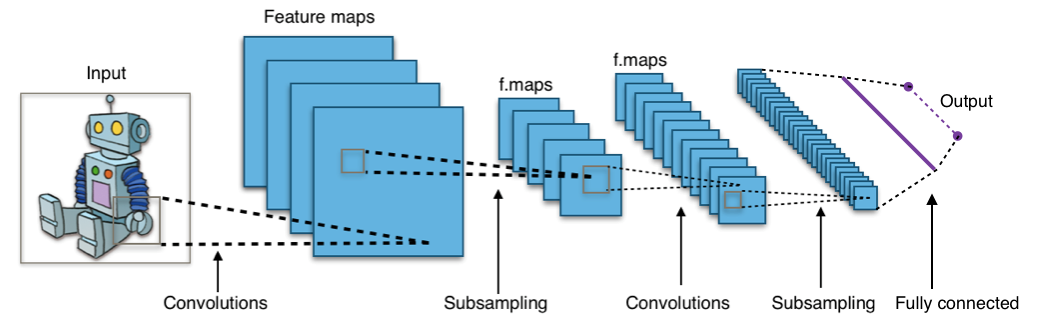
En répétant plusieurs fois l’opération, on va réduire le nombre de calculs.
Deep learning et intelligence artificielle
Le « deep learning », ou apprentissage profond en anglais, est un sous-domaine de l’apprentissage automatique qui est l’art de programmer un ordinateur afin qu’il soit capable d’apprendre de façon autonome et à partir d’exemples. Il permet de faire apprendre à un ordinateur une tâche précise en observant un grand nombre d’exemples. Cette technique utilise toutes les bases de données pour créer des modèles de reconnaissance d’image.
Les scientifiques se sont plutôt intéressés au fonctionnement du cortex cérébral des vertébrés. C’est à partir de ces observations qu’ils se sont inspiré pour créer les modèles de reconnaissance d’images par apprentissage profond.
Pour la reconnaissance d’image par apprentissage profond, on utilise de façon quasi-systématique les réseaux de neurones convolutifs. La convolution est un outil mathématiques simple qui agit comme un filtrage.
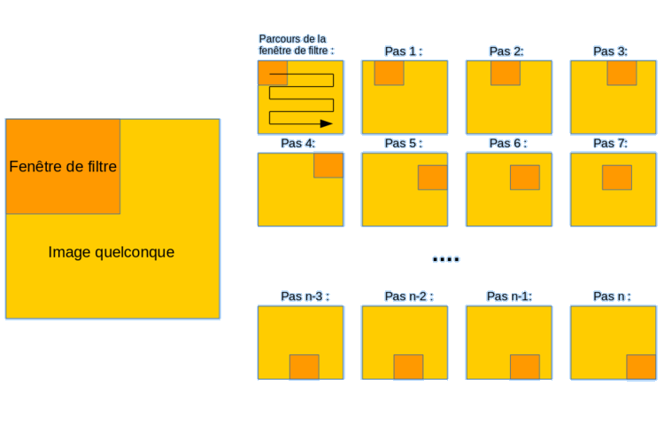
On définit une taille de fenêtre qui va se balader à travers toute l’image (il faut bien se rappeler qu’une image peut être vue comme étant un tableau). Au tout début de la convolution, la fenêtre sera positionnée tout en haut à gauche de l’image puis elle va se décaler d’un certain nombre de cases (c’est ce que l’on appelle le pas) vers la droite et lorsqu’elle arrivera au bout de l’image, elle se décalera d’un pas vers le bas ainsi de-suite jusqu’à ce que le filtre ait parcouru la totalité de l’image.
Pour qu’une intelligence artificielle soit la plus performante dans la reconnaissance d’images, il faut lui donner une base de données la plus grande possible. Par exemple, si l’on veut qu’elle reconnaisse à coup sûr un chat, on va lui inculquer un maximum de photos de chats en lui indiquant que sur chaque image, il y a un chat. Grâce aux réseaux neuronaux que l’on vient de voir, le système informatique pourra facilement identifier si ce qu’il « voit » est un chat ou non ! C’est le fonctionnement basique du deep learning, mais pour aller plus loin, il va être capable de se corriger lui-même et d’apprendre de ses erreurs, c’est l’étape d’après.

Conclusion
Nous ne parlerons pas ici des différentes applications de la vision par ordinateur (sous-domaine de l’intelligence artificielle), mais sachez qu’elles sont vraiment très nombreuses : reconnaissance faciale, voitures autonomes, reconnaissance d’objets, etc.
L’intelligence artificielle s’invite dans nos vies et les caméras se font de plus en plus nombreuses, notamment en Chine avec le « contrôle social » ou encore via les divers et nombreux objets connectés qui envahissent peu à peu nos habitations.
Bref, nous n’en avons pas fini avec ces nouvelles technologies, elles continuent de s’améliorer avec le temps et permettent de faire toujours plus de choses !


