


Vous avez forcément déjà croisé ce terme : « Big Data ». Il est sur toutes les lèvres, des experts en marketing aux ingénieurs, en passant par les journalistes. On l’associe à l’intelligence artificielle, aux GAFAM, à la publicité ciblée… Mais concrètement, de quoi s’agit-il ? Loin d’être un concept abstrait réservé à une élite de la tech, le Big Data est une révolution qui façonne déjà votre quotidien, de la série que Netflix vous recommande ce soir à l’itinéraire que Waze calcule pour vous éviter les bouchons.
Dans ce guide complet, nous allons démystifier ce phénomène. Nous commencerons par les bases, avec des exemples que tout le monde peut comprendre, avant de plonger sous le capot pour les plus curieux d’entre vous. Attachez vos ceintures, on vous explique tout.
Le Big Data, les fondations pour tout comprendre
Si vous deviez expliquer le Big Data à vos grands-parents, vous pourriez commencer par une analogie simple : celle de la bibliothèque. Autrefois, une bibliothèque contenait des livres, bien rangés, faciles à cataloguer. C’était l’ère de la « data » classique. Maintenant, imaginez que cette bibliothèque reçoive chaque seconde des millions de nouveaux ouvrages, mais aussi des magazines, des photos, des notes manuscrites, des enregistrements audio, des vidéos… dans toutes les langues. Il devient impossible de tout stocker au même endroit et de tout classer avec les anciennes méthodes. Le Big Data, c’est exactement ça : le défi posé par cette avalanche de données et les nouvelles technologies inventées pour lui donner un sens.
Au-delà des « 3 V » : les 5 dimensions du Big Data
Pour définir ce phénomène, les experts ont d’abord parlé des « 3 V ». C’est un moyen très efficace de comprendre son ADN, mais aujourd’hui, le modèle des « 5 V » est plus complet et plus juste.

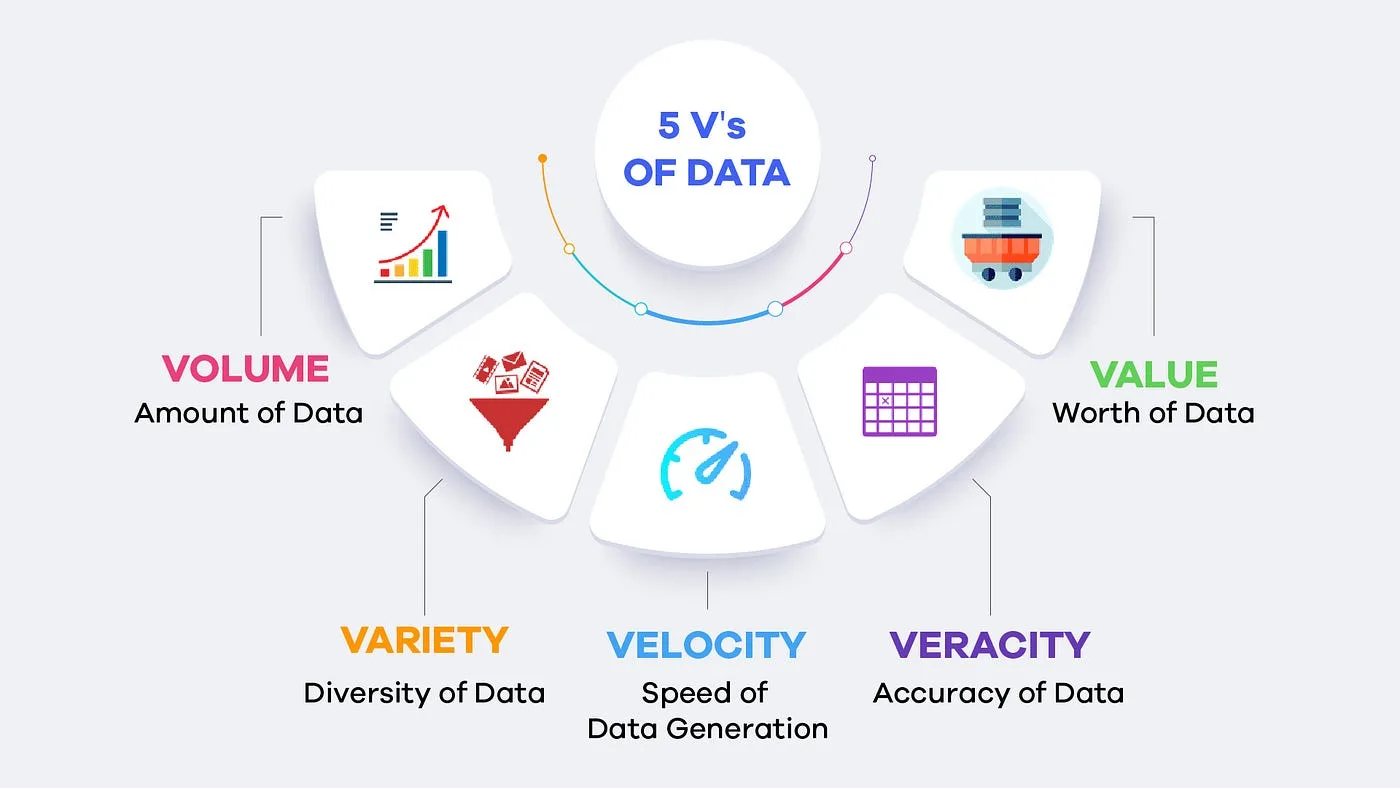
- Le Volume : C’est la caractéristique la plus évidente. On parle de quantités de données astronomiques. Oubliez les gigaoctets de votre disque dur ; ici, l’unité de mesure est le pétaoctet, l’exaoctet, voire le zettaoctet. On estime que l’humanité génère chaque jour plus de 2,5 exaoctets de données, l’équivalent de plus de 5 millions d’ordinateurs portables remplis à ras bord.
- La Vélocité : Ces données ne sont pas seulement massives, elles arrivent à une vitesse vertigineuse et en continu. Pensez aux milliards de « likes » sur les réseaux sociaux, aux données de géolocalisation de votre smartphone, aux transactions par carte bancaire chaque seconde, ou encore aux informations envoyées par les milliers de capteurs d’un avion en plein vol.
- La Variété : Autrefois, les données étaient « structurées » et bien organisées. Le Big Data inclut une immense majorité de données « non structurées » : le texte d’un e-mail, une photo, une vidéo, un commentaire sur un site web, un enregistrement vocal… C’est ce chaos apparent qui recèle une valeur immense.
- La Véracité : C’est une dimension cruciale. La donnée peut être massive, mais si elle est fausse, incomplète ou imprécise, elle est inutile, voire dangereuse. Garantir la qualité et la fiabilité des données est un défi majeur du Big Data. C’est le principe du « Garbage In, Garbage Out » : si vous entrez des ordures, il en sortira des ordures.
- La Valeur : C’est la finalité de tout le processus. Collecter des données pour le plaisir ne sert à rien. Le Big Data n’a d’intérêt que s’il permet de générer de la valeur : prendre de meilleures décisions, créer de nouveaux produits, réaliser des économies, améliorer la vie des gens…
Vous avez compris les bases ? Parfait. Vous savez maintenant que le Big Data est un déluge de données diverses et rapides, dont la valeur dépend de sa fiabilité. Si votre curiosité est piquée et que vous voulez savoir ce qui se passe sous le capot, continuez votre lecture. Nous allons maintenant explorer l’architecture, les technologies et les cas d’usages concrets qui rendent tout cela possible.
Sous le capot du Big Data
Faire face aux « 5 V » a nécessité de réinventer complètement la manière dont on stocke et on traite l’information. Les bases de données traditionnelles n’étaient tout simplement pas conçues pour une telle échelle.
Stocker l’inconcevable : le stockage distribué
L’idée fondamentale du Big Data est simple : puisqu’aucun ordinateur n’est assez puissant pour tout gérer, nous allons en utiliser des milliers en même temps. C’est le principe du stockage distribué. Au lieu d’un disque dur géant et coûteux, on répartit les données sur un grand nombre de serveurs standards, que l’on appelle un « cluster ». Le système le plus célèbre pour cela est Hadoop (et son système de fichiers HDFS), un projet open-source initié par Google. Il assure la répartition des données et leur sécurité : chaque morceau de donnée est copié plusieurs fois sur différents serveurs. Ainsi, si un serveur tombe en panne, l’information n’est jamais perdue.
Analyser le chaos : le traitement parallèle et le Machine Learning
Une fois les données stockées, il faut les traiter. Là encore, on divise pour mieux régner grâce au traitement parallèle. Le modèle historique MapReduce a été largement supplanté par Apache Spark, beaucoup plus rapide, car il travaille en mémoire vive. Mais ces outils ne sont que des moteurs. Le véritable pilote est le Machine Learning, une branche de l’IA. En « nourrissant » des algorithmes avec ces immenses volumes de données, on les « entraîne » à reconnaître des schémas et à faire des prédictions. Le Big Data n’est donc pas une fin en soi, c’est le carburant indispensable au fonctionnement de l’Intelligence Artificielle moderne.
Des cas d’usages concrets qui changent la donne
Les exemples de Netflix ou Spotify sont connus, mais le Big Data infuse des secteurs bien plus critiques. Dans la santé, l’analyse de millions de génomes permet d’accélérer la recherche sur des maladies comme le cancer et de développer des traitements personnalisés. Dans l’industrie 4.0, des milliers de capteurs sur une chaîne de production permettent la « maintenance prédictive » : une IA peut anticiper la panne d’une pièce avant même qu’elle ne se produise, évitant des arrêts coûteux. Dans la finance, les algorithmes de détection de fraude analysent des milliards de transactions en temps réel pour bloquer une utilisation suspecte de votre carte bancaire avant même que vous ne vous en rendiez compte. Enfin, dans le retail, des géants comme Amazon optimisent en permanence leurs stocks et leurs tournées de livraison en analysant les commandes, le trafic routier et même les prévisions météo.
Big Data, une révolution en marche et ses défis
Vous l’aurez compris, le Big Data est bien plus qu’un simple mot à la mode. C’est le socle technologique sur lequel repose une grande partie de l’innovation numérique actuelle. En permettant de collecter, stocker et analyser des volumes de données autrefois inimaginables, il ouvre la voie à des services plus personnalisés, à une science plus rapide et à une industrie plus efficace. Mais c’est aussi une puissance qui nous oblige à nous poser collectivement les bonnes questions sur l’usage que nous voulons en faire, sur la protection de notre vie privée (un enjeu majeur du RGPD), et sur l’éthique des algorithmes qu’il alimente. Une révolution fascinante, qui a créé de nouveaux métiers (Data Scientist, Data Engineer…) et que nous continuerons de suivre pour vous.
Big Data : questions fréquentes
C’est une excellente question. Imaginez le Big Data comme une immense bibliothèque brute et désorganisée. La Data Science, c’est le travail du bibliothécaire expert (le Data Scientist) qui utilise des outils (statistiques, programmation, Machine Learning) pour trouver des livres pertinents, les analyser, comprendre leurs liens et en extraire une connaissance nouvelle et utile. Le Big Data est donc souvent le « terrain de jeu » de la Data Science.
Non, pas du tout. Ils coexistent car ils répondent à des besoins différents. Les bases de données SQL sont parfaites pour des données structurées et garantissent une grande fiabilité des transactions (ex: un système bancaire). Le Big Data (avec des technologies NoSQL) est conçu pour gérer d’énormes volumes de données variées et non structurées où la vitesse et la flexibilité sont plus importantes que la cohérence transactionnelle à l’instant T. Beaucoup d’entreprises utilisent les deux.
Il existe plusieurs portes d’entrée. Un « Data Engineer » se concentre sur la construction de l’architecture pour collecter et stocker les données (avec des outils comme Spark, Hadoop). Un « Data Analyst » utilise les données pour créer des rapports et des visualisations. Un « Data Scientist » utilise les mathématiques et le Machine Learning pour faire des prédictions. Pour débuter, des compétences en programmation (Python est roi), en statistiques et une connaissance des bases de données sont essentielles.
Aujourd’hui, oui, dans la quasi-totalité des cas. Des plateformes comme Amazon Web Services (AWS), Google Cloud Platform (GCP) et Microsoft Azure offrent des services de Big Data « à la demande ». Cela évite aux entreprises de devoir acheter et maintenir des milliers de serveurs elles-mêmes. Elles peuvent louer la puissance de calcul dont elles ont besoin, ce qui a démocratisé l’accès à ces technologies.