Anthropic a lancé Claude Opus 4.8 le 28 mai 2026, une mise à jour de son modèle haut de gamme. Claude Opus 4.8 améliore les performances sur la plupart des tests de référence, mais son vrai changement tient ailleurs : le modèle signale plus volontiers ses doutes et ses erreurs. Il arrive avec de nouvelles fonctions et un mode rapide moins coûteux, sans hausse de prix.
Anthropic décrit cette version comme une progression « modeste mais tangible » par rapport à Opus 4.7. Voici ce qui change concrètement, des capacités aux tarifs.
Qu’est-ce que Claude Opus 4.8 ?
Opus 4.8 est le modèle haut de gamme d’Anthropic, destiné aux tâches complexes. Il succède à Opus 4.7 et se place juste sous la classe Mythos dans la hiérarchie de capacités de l’éditeur. Sur claude.ai, il figure dans le sélecteur sous la mention « For complex tasks ».
Le modèle joue aussi un rôle de filet de sécurité. Quand le modèle public le plus puissant, Fable 5, détecte une requête sensible, c’est Opus 4.8 qui prend le relais pour répondre.
Si vous hésitez entre les différents modèles de la gamme, notre guide pour choisir le bon modèle Claude vous aidera à y voir plus clair.
Ce que Opus 4.8 améliore
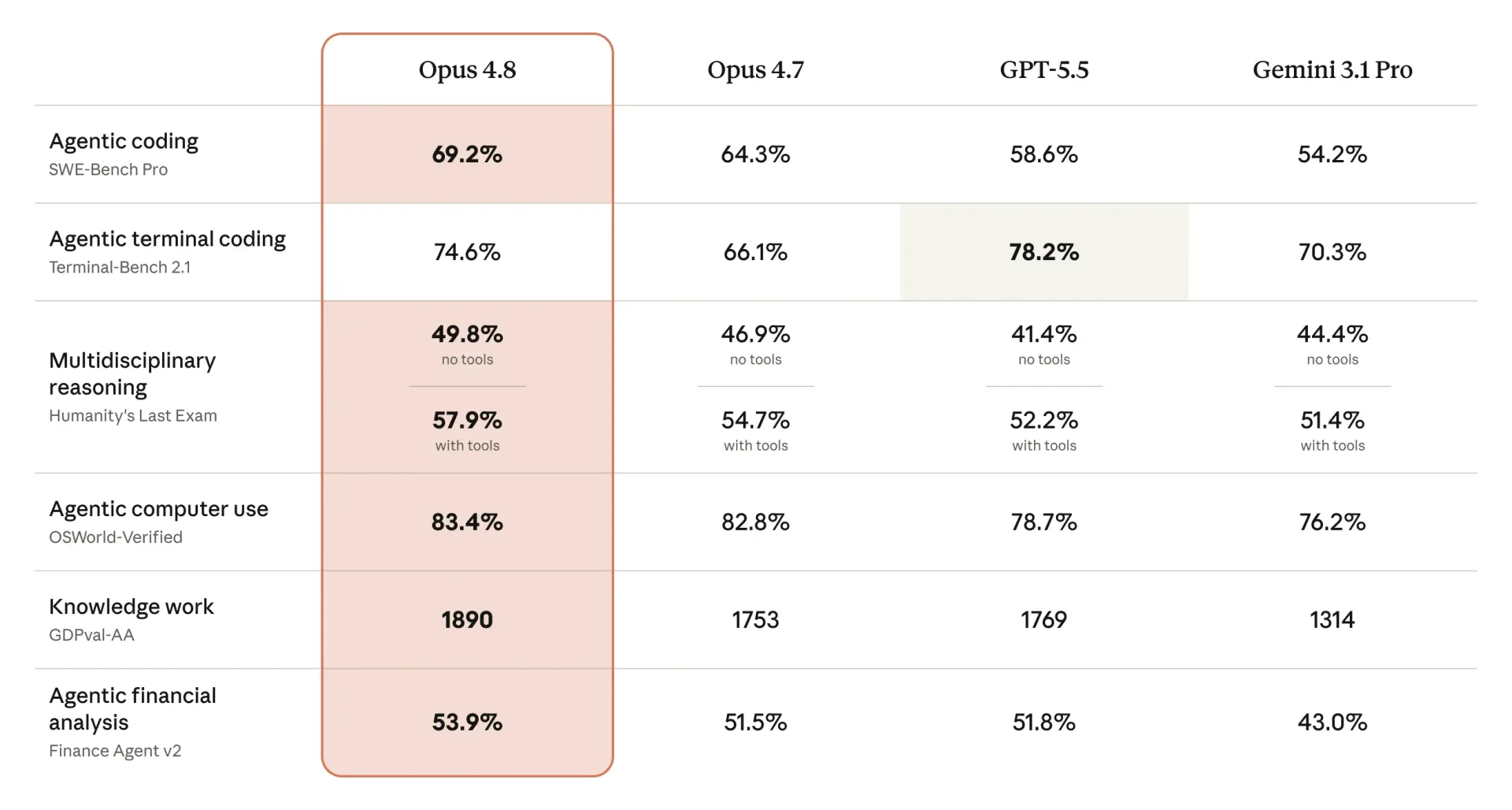
Claude Opus 4.8 progresse sur quatre terrains : le code, les compétences agentiques, le raisonnement et le travail de connaissance. Sur le test SWE-bench Pro, la variante la plus difficile pour le développement logiciel, il atteint 69,2 %, contre 64,3 % pour Opus 4.7.
Anthropic revendique un avantage sur GPT-5.5 d’OpenAI dans la majorité des tests, notamment en travail de connaissance, en code et en usage d’outils. GPT-5.5 conserve toutefois l’avantage sur les workflows en terminal, où il reste devant.
Le modèle corrige aussi des défauts d’Opus 4.7 signalés par les développeurs, comme des commentaires trop verbeux et des problèmes d’appels d’outils. Ces correctifs comptent pour les usages automatisés qui tournent sans supervision.
Opus 4.8 et l’honnêteté du modèle
La principale avancée de Claude Opus 4.8 concerne sa franchise. Le modèle signale plus souvent ses incertitudes et avance moins d’affirmations non étayées. Selon Anthropic, il laisse environ quatre fois moins passer de défauts dans son propre code sans les signaler, par rapport à Opus 4.7.
Des testeurs en entreprise confirment ce point. Le fonds Bridgewater note que la principale différence tient à la tendance du modèle à pointer de lui-même les problèmes dans les données et les résultats, là où d’autres modèles laissaient ce travail à l’utilisateur.
Cette qualité ne se voit pas dans une démonstration ponctuelle. Elle se révèle sur les sessions longues et autonomes, où une erreur non signalée peut se propager pendant des heures.
Les nouveautés lancées avec Claude Opus 4.8
Opus 4.8 s’accompagne de trois nouveautés. La plus visible côté grand public est le contrôle de l’effort, déjà présent sur le sélecteur de claude.ai, qui ajuste la profondeur de réflexion du modèle selon la difficulté de la tâche.
Les workflows dynamiques
Les workflows dynamiques permettent à Claude Code de s’attaquer à des problèmes d’ingénierie de grande ampleur. Le modèle planifie le travail au fur et à mesure, lance des centaines de sous-agents en parallèle et décide seul quand approfondir, revenir en arrière ou terminer.
Anthropic indique que Claude Code peut désormais gérer des migrations couvrant des centaines de milliers de lignes, de la planification jusqu’à la fusion du code. Cette fonction est proposée en aperçu de recherche sur les offres Enterprise, Team et Max.
Le mode rapide
Le mode rapide fait tourner Opus 4.8 à 2,5 fois la vitesse standard. Anthropic annonce qu’il coûte trois fois moins cher que le mode rapide des modèles précédents, ce qui le rend plus accessible pour les usages à fort volume.
Côté développeurs, l’API Messages accepte aussi des instructions système au sein de la liste des messages. Cela permet de modifier les consignes en cours de tâche sans casser le cache, un gain utile sur les longues sessions d’agents.
Combien coûte Claude Opus 4.8 ?
Opus 4.8 coûte 5 dollars par million de tokens en entrée et 25 dollars par million de tokens en sortie sur l’API. Ce tarif est identique à celui d’Opus 4.7, sans hausse malgré les gains de performances.
Le mode rapide est facturé à part, à 10 dollars par million de tokens en entrée et 50 dollars en sortie. Sur claude.ai, Opus 4.8 reste accessible via les abonnements payants, du forfait Pro aux formules Max.
Faut-il choisir Claude Opus 4.8 ou Fable 5 ?
Le choix entre Opus 4.8 et Fable 5 dépend de la difficulté de la tâche. Opus 4.8 convient aux travaux complexes du quotidien professionnel, tandis que Fable 5 vise les missions les plus longues et les plus exigeantes, où son avance se creuse.
Opus 4.8 garde un atout : il consomme moins de quota et reste souvent suffisant. Pour comprendre quand passer au modèle supérieur, consultez notre article dédié à Claude Fable 5. Le détail des benchmarks figure sur l’annonce officielle d’Anthropic.
Questions fréquentes
Claude Opus 4.8 améliore le code, le raisonnement et le travail de connaissance par rapport à Opus 4.7. Son principal apport reste l’honnêteté : il signale environ quatre fois moins de défauts non flagués dans son code et avance moins d’affirmations non étayées.
Sur l’API, Claude Opus 4.8 coûte 5 dollars par million de tokens en entrée et 25 dollars en sortie, soit le même tarif qu’Opus 4.7. Le mode rapide est facturé 10 dollars en entrée et 50 dollars en sortie.
Les workflows dynamiques permettent à Claude Code de gérer de très grands projets en planifiant le travail au fil de l’eau et en lançant des centaines de sous-agents. La fonction est en aperçu de recherche sur les offres Enterprise, Team et Max.
Anthropic affirme que Claude Opus 4.8 devance GPT-5.5 sur la majorité des tests, notamment en code, usage d’outils et travail de connaissance. GPT-5.5 garde l’avantage sur les workflows en terminal, où il reste devant.